연결 리스트
17.1 내장된 참조(Embedded references)
우리는 다른 객체를 참조하는 속성들의 예를 본 바 있습니다. 이것을 내장된 참조(embedded references)라고 부릅니다 (Section 12.8 참조). 일반적인 데이타 구조인 연결 리스트(linked list)가 이 특징을 이용합니다.
연결 리스트는 노드(nodes)로 구성되는데, 각 노드는 리스트에서 다음 노드에 대한 참조점을 포함합니다. 게다가, 각 노드는 카르고(cargo)라고 부르는 한 단위의 데이타를 포함합니다.
연결 리스트는 재귀적인 정의를 가지기 때문에 재귀 데이타 구조(recursive data structure)로 간주됩니다.
연결 리스트는 다음과 같이:
- None으로 표현되는, 비어있는 리스트이거나,
- 카르고(cargo) 객체와 연결리스트에 대한 참조점을 포함하는 노드입니다.
재귀 데이타 구조는 재귀적인 메쏘드에 알맞습니다.
17.2 Node 클래스
새롭게 클래스 하나를 만들때와 마찬가지로, 새로운 형을 보여주고 만드는 기본적인 메카니즘을 테스트할 수 있도록 초기화 메쏘드와 __str__ 메쏘드로 시작하겠습니다:
class Node:
def __init__(self, cargo=None, next=None):
self.cargo = cargo
self.next = next
def __str__(self):
return str(self.cargo)
보통때와 같이, 초기화 메쏘드에 대한 매개변수들은 선택적입니다. 기본값으로 카르고와 링크는, 즉 next는 모두 None으로 설정됩니다.
한 노드의 문자열 표현은 단지 카르고의 문자열 표현일 따름입니다. 어떤 값도 str 함수에 건네질 수 있으므로, 리스트에 는 어떤 값도 저장할 수 있습니다.
지금까지 구현한 것을 테스트 해보려면, Node를 만들고 그것을 출력하면 됩니다:
>>> node = Node("test")
>>> print node
test
더 재미있게 하려면, 하나의 노드 이상을 가진 리스트가 필요합니다:
>>> node1 = Node(1)
>>> node2 = Node(2)
>>> node3 = Node(3)
이 코드는 세 개의 노드를 만듭니다, 그러나 그 노드들이 아직 연결(linked)된 것은 아니기 때문에 리스트를 가진 것은 아닙니다. 상태 다이어그램은 이렇게 보입니다:
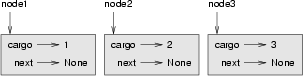
노드들을 연결하려면, 첫 번째 노드가 두 번째 노드를 가리키게 만들고 두 번째 노드는 세 번째 노드를 가리키게 만들어야 합니다:
>>> node1.next = node2
>>> node2.next = node3
세 번째 노드가 가진 참조점은 None인데, 이것은 그 노드가 리스트의 마지막임을 나타내 줍니다. 이제 상태 다이어그램은 이렇게 보입니다:
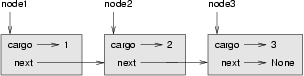
이제 여러분은 노드를 만들고 그것들을 리스트에 링크하는 법을 배웠습니다. 이 시점에서 약간 분명하지 않은 것은 왜 그렇게 해야 하는 것이냐 하는 것입니다.
17.3 집단으로서의 리스트(Lists as collections)
리스트의 유용성은 여러 객체들을 하나의 개체로 조립하는 방법을 제공하기 때문입니다. 때로는 이 개체를 집단(collection)이라고 부릅니다. 예제에서, 리스트의 첫 번째 노드는 전체 리스트에 대한 참조점으로 작용합니다.
리스트를 매개변수로 건네주려면 첫 번째 노드를 가르키는 참조점을 건네주기만 하면 됩니다. 예를 들어, printList 함수는 한개의 노드를 인수로 취합니다. 리스트의 머리에서 시작하여, 그 함수는 각 노드를 마지막에 다다를 때까지 출력합니다. :
def printList(node):
while node:
print node,
node = node.next
print
이 메쏘드에 요청하기 위해, 첫 번째 노드에 대한 참조점을 건넵니다:
>>> printList(node1)
1 2 3
printList안에는 리스트의 첫 번째 노드에 대한 참조점이 있습니다. 그러나 거기에는 다른 노드들에 대한 참조점을 가지는 어떠한 변수도 없습니다. 각 노드로부터 next 값을 사용하여 다음 노드를 얻어야 합니다.
연결 리스트를 순회하려면, node와 같은 회돌이 변수를 사용하여 각각의 다른 노드들을 연속적으로 참조하는 것이 일반적입니다.
다음 다이어그램은 list의 값과 node가 취하는 값들을 보여줍니다:
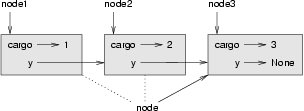
관례적으로, 리스트는 [1, 2, 3]와 같이, 보통 그 요소들은 컴마로 분리되고, 각괄호에 쌓여서 출력됩니다. 연습으로, printList를 수정하여 이런 형식으로 출력을 만들어 보세요.
17.4 리스트와 재귀
재귀적인 메쏘드를 사용하면 자연스럽게 많은 리스트 연산을 표현할 수 있습니다. 예를 들어, 다음은 리스트를 거꾸로 출력하는 재귀적인 알고리즘입니다:
- 리스트를 두 개의 조각으로 분리한다: 첫 번째 노드 (머리(head)라고 부른다)와; 그리고 그 나머지 (꼬리(tail)라고 부른다).
- 꼬리를 거꾸로 출력한다.
- 머리를 출력한다.
물론, 2 단계는, 재귀 호출이므로, 우리가 리스트를 거꾸로 출력하는 방법을 가지고 있다고 가정합니다. 그러나 만약 그 재귀 호출이 작동한다고---신념에 찬 도약으로---가정한다면 우리는 이 알고리즘이 작동한다고 확신할 수 있습니다.
필요한 모든 것은 기저 케이스와 모든 리스트에 대하여 그것을 증명하는 방법이며, 결국 우리는 기저 케이스에 도착할 것입니다. 리스트를 재귀적으로 정의하면, 자연스럽게 기저 케이스는 빈 리스트이며, None으로 표현됩니다:
def printBackward(list):
if list == None: return
head = list
tail = list.next
printBackward(tail)
print head,
첫 번째 라인은 아무것도 하지 않음으로써 기저 케이스를 처리합니다. 다음의 두 라인은 리스트를 머리(head)와 꼬리(tail)로 분리합니다. 마지막 두 라인은 리스트를 인쇄합니다. 마지막 라인의 쉼표는 파이썬이 각 노드를 인쇄한 후에 새로운라인(newline)을 인쇄하지 못하도록 합니다.
printList에 요청한 것처럼 우리는 다음과 같이 이 메쏘드를 요청합니다 :
>>> printBackward(node1)
3 2 1
결과는 거꾸로 된 리스트입니다.
여러분은 왜 printList와 printBackward가 함수이며 Node 클래스의 메쏘드가 아닌지 궁금할 것입니다. 이유는 우리가 None을 사용하여 빈 리스트를 표현하기를 원하고 None에 있는 메쏘드에 요청하는 것은 적법하지 않기 때문입니다. 이러한 제한 때문에 산뜻한 객체-지향 스타일로 리스트-처리 코드를 작성하는 것은 어색합니다.
printBackward가 항상 종료할 것이라는 것을 증명할 수 있을까요? 다른 말로 하면, 그것은 항상 기저 케이스에 도달할까? 사실, 대답은 아니오입니다. 어떤 리스트에서 이 메쏘드는 충돌할 것입니다.
17.5 무한 리스트(Infinite lists)
한 노드는 리스트에서, 그 자신을 포함하여, 이전의 노드를 거꾸로 참조할 수 있습니다. 예를 들어, 다음 그림은 두 개의 노드를 가진 리스트를 보여주는데, 그 중의 하나는 자기 자신을 참조하고 있습니다:
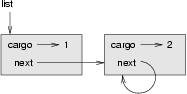
만약 이 리스트에 대하여 printList를 요청하면, 영원히 회돌이를 돌 것입니다. 만약 printBackward를 요청하면, 무한대로 재귀할 것입니다. 이러한 종류의 행위 때문에 무한 리스트는 다루기가 어렵습니다.
그럼에도 불구하고, 무한 리스트는 종종 쓸모가 있습니다. 예를 들어, 하나의 숫자를 디지트의 리스트로 표현할 수 있습니다. 그리고 무한 리스트를 사용하면 반복적인 분수를 표현할 수 있습니다.
그것과는 상관없이, printList와 printBackward가 끝난다는 것을 증명할 수 없다는 것은 문제입니다. 우리가 할수 있는 최선은 다음의 가설입니다, "만약 리스트가 회돌이를 포함하고 있지 않다면, 이러한 메쏘드들은 종료할 것이다." 이러한 종류의 주장을 전제조건(precondition)이라고 부릅니다. 매개변수들중의 하나에 제한을 가합니다 그리고 만약 그 제한이 만족되면 그 메쏘드의 행위를 기술합니다. 곧 더 많은 예제들을 보여 드리겠습니다.
17.6 근본적인 모호성 공리(ambiguity theorem)
어쩌면 printBackward의 일부를 보고 놀랄지도 모르겠습니다:
head = list
tail = list.next
첫 번째 할당후에, head와 list는 같은 형과 같은 값을 가집니다. 그러면 왜 새로운 변수를 만들었을까?
이유는 두 변수들이 서로 다른 임무를 수행하기 때문입니다. 우리는 head를 한개의 노드에 대한 참조점으로 간주하고, list를 리스트의 첫 번째 노드에 대한 참조점으로 간주합니다. 이러한 "임무"는 프로그램의 부분은 아닙니다; 그 임무는 프로그래머의 마음에 있습니다.
일반적으로 프로그램을 보고서는 변수 하나가 어떤 임무를 수행하는지 알 수 없습니다. 이 모호성은 유용할 수 있습니다. 그러나 또한 프로그램을 읽기 어렵게 만들 수 있습니다. 우리는 가끔 node와 list같은 변수 이름들을 사용하여 우리가 변수를 어떻게 사용하기를 원하는지 문서화하거나 때로는 추가로 변수들을 만들어서 모호성을 없애기도 합니다.
우리는 head와 tail 없이 printBackward를 작성할 수 있습니다. 이렇게 하면 더욱 간단하기는 하겠지만 불분명해질 가능성이 더 높습니다:
def printBackward(list) :
if list == None : return
printBackward(list.next)
print list,
두 개의 함수 호출을 보고서, 우리는 printBackward가 그의 인수들을 집단으로 취급한다는 사실을 기억해야 합니다. 그리고 print는 그의 인수들을 하나의 객체로 취급한다는 사실을 기억해야 합니다.
근본적인 모호성 공리(fundamental ambiguity theorem)란 한 노드에 대한 참조점에 내재하는 모호성을 말합니다:
한 노드를 가리키는 변수는 그 노드를 단일 객체로 취급할 수도 있고 또는 노드들을 담은 리스트에서 첫 번째 노드로 취급할 수도 있다.
17.7 리스트를 수정하기
두가지 방법으로 연결리스트를 수정할 수 있습니다. 분명히, 우리는 한 노드의 카르고를 변경할 수 있습니다. 그러나 더 흥미있는 연산은 노드를 더하고, 제거하며, 또는 재조직하는 것입니다.
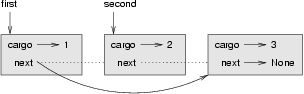
예제로, 리스트에서 두 번째 노드를 제거하고 제거된 노드의 참조점을 반환하는 메쏘드 하나를 작성해 봅시다:
def removeSecond(list):
if list == None: return
first = list
second = list.next
# make the first node refer to the third
first.next = second.next
# separate the second node from the rest of the list
second.next = None
return second
다시, 임시 변수를 사용하여 코드를 더 읽기 쉽게 합니다. 다음은 이 메쏘드를 사용하는 방법입니다:
>>> printList(node1)
1 2 3
>>> removed = removeSecond(node1)
>>> printList(removed)
2
>>> printList(node1)
1 3
이 상태 다이어그램은 연산의 효과를 보여줍니다:
만약 이 메쏘드를 요청하면서 오직 하나의 요소만을 가진 리스트를 넘겨주면 어떤 일이 일어나는가(싱글턴(singleton))? 만약 빈 리스트를 인수로 건네주면 어떤 일이 일어나는가? 이 메쏘드에 대하여 전제조건이 있는가? 그렇다면, 그 메쏘드를 수정하여 현명하게 전제조건의 위반을 처리해 보세요.
17.8 포장자(Wrappers)와 도움자(helpers)
하나의 리스트 연산을 두 개의 메쏘드로 분리하면 종종 유용합니다. 예를 들어, 리스트를 관례적인 리스트 형태인 [3, 2, 1]로 거꾸로 인쇄하려면 printBackward 메쏘드를 사용하여 3, 2,를 인쇄할 수 있지만 양쪽의 각괄호와 첫 번째 노드를 인쇄할 메쏘드가 따로 필요합니다. 그 메쏘드를 printBackwardNicely이라고 불러 봅시다:
def printBackwardNicely(list) :
print "[",
if list != None :
head = list
tail = list.next
printBackward(tail)
print head,
print "]",
역시, 좋은 생각은 이러한 메쏘드들을 점검하여 빈 리스트 혹은 싱글턴과 같은 특별한 경우에 잘 작동하는지 알아 보는 것입니다.
프로그램 어딘가에 이 메쏘드를 사용할 때, printBackwardNicely를 직접적으로 요청을 하면, 이 메쏘드는 우리 대신에 printBackward를 요청합니다. 그런 의미에서, printBackwardNicely는 포장자(wrapper)로 작동합니다. 그리고 printBackwardNicely는 printBackward를 도움자(helper)로 사용합니다.
17.9 LinkedList 클래스
우리가 리스트를 구현하고 있는 방식에는 약간 미묘한 문제가 있습니다. 원인과 결과를 거꾸로 하여, 대안적인 구현을 먼저 제시하겠습니다. 그리고 나서 그 구현이 어떤 문제들을 해결하는지 설명하겠습니다.
먼저, LinkedList라고 부르는 새로운 클래스 하나를 만들겠습니다. 이 클래스의 속성은 정수로서 리스트의 길이와 첫 번째 노드에 대한 참조점을 포함합니다. LinkedList 객체는 Node객체들을 담은 리스트를 조작하기 위한 처리자로 작동합니다:
class LinkedList :
def __init__(self) :
self.length = 0
self.head = None
LinkedList 클래스에 대하여 한 가지 좋은 점은 이 클래스가 printBackwardNicely와 같은 포장자(wrapper) 함수를 배치하기에 자연스러운 곳이라는 것입니다. 포장자 함수를 LinkedList 클래스의 메쏘드로 만들 수 있습니다:
class LinkedList:
...
def printBackward(self):
print "[",
if self.head != None:
self.head.printBackward()
print "]",
class Node:
...
def printBackward(self):
if self.next != None:
tail = self.next
tail.printBackward()
print self.cargo,
그냥 복잡하게 만들어 혼란을 유도하기 위해, printBackwardNicely의 이름을 바꾸었습니다. 이제 printBackward라는 이름의 메쏘드가 두 개 있습니다: 하나는 Node 클래스(도움자)에 있으며; 그리고 하나는 LinkedList 클래스(포장자)에 있습니다. 포장자가 self.head.printBackward를 요청하면, 이 메쏘드는 도움자를 호출합니다. 왜냐하면 self.head는 Node 객체이기 때문입니다.
LinkedList 클래스의 또 다른 혜택은 리스트의 첫 번째 요소를 더 쉽게 추가하거나 제거할 수 있게 하여 준다는 것입니다. 예를 들어, addFirst는 LinkedList들을 위한 메쏘드입니다; 이 메쏘드는 카르고 한 항목을 인수로 취하고 그것을 그 리스트의 처음에 배치합니다:
class LinkedList:
...
def addFirst(self, cargo):
node = Node(cargo)
node.next = self.head
self.head = node
self.length = self.length + 1
평상시와 마찬가지로, 여러분은 이러한 코드를 점검하여 특수한 경우들을 처리하는지를 살펴보아야 합니다. 예를 들어, 그 리스트가 처음부터 비어 있다면 무슨일이 일어나는가?
17.10 불변량(Invariants)
어떤 리스트들은 "잘 구성되어" 있습니다; 다른 리스트들은 그렇지 않습니다. 예를 들어, 만약 리스트가 회돌이를 포함하고 있다면, 그 리스트에서 메쏘드중 많은 메쏘드들은 충돌할 것입니다. 그래서 리스트가 어떤 회돌이도 포함하고 있지 않기를 요구하고 싶을 것입니다. 또 다른 요구조건은 LinkedList 객체에 있는 length 값이 그 리스트에 있는 노드의 실제 개수와 동등해야 한다는 것입니다.
이러한 요구조건들을 불변량(invariants)이라고 부르는데 왜냐하면, 이상적으로, 그것들은 모든 객체에 대하여 언제나 참이어야 하기 때문입니다. 객체에 대하여 불변량을 지정하는 것은 유용한 프로그래밍 관습입니다. 왜냐하면 그렇게 하면 더 쉽게 코드의 정확성을 증명할 수 있고, 더 쉽게 데이타 구조의 무결성을 점검할 수 있으며, 더 쉽게 에러를 탐지할 수 있기 때문입니다.
불변량에 대하여 가끔식 혼동되는 일 하나는 어떤 때는 불변량이 위반될 때가 있다는 것입니다. 예를 들어, addFirst의 중간에서, 노드를 추가한 후에 그렇지만 length를 증가시키기 전에는, 불변량이 위반됩니다. 이런 종류의 위반은 받아들일 수 있습니다; 사실, 적어도 잠시 동안 불변량을 위반하지 않고서는 객체를 변경하기가 종종 불가능한 경우가 있습니다. 보통, 불변량을 위반하는 어느 메쏘드도 반드시 그 불변량을 복구하도록 요구합니다.
불변량을 무시하는 코드가 상당정도로 길어진다면, 주석을 달아, 그 불변량에 의존하는 연산들이 수행되지 않도록 그 상황을 분명하게 해 두는 것이 중요합니다.
17.11 용어 해설
- 내장된 참조점(embedded reference)
- 객체의 속성에 저장된 참조점.
- 연결 리스트(linked list)
- 일련의 연결 노드를 사용하여 집단을 구현하는 데이타 구조.
- 노드(node)
- 리스트의 한 요소, 같은 형의 또 다른 객체에 대한 참조점을 담고 있는 객체로 일반적으로 구현된다.
- 카르고(cargo)
- 한 노드에 포함된 데이타 항목.
- 링크(link)
- 한 객체를 또 다른 객체에 연결하는데 사용되는 내장된 참조점.
- 전제조건(precondition)
- 한 메쏘드가 올바르게 작동하기 위해 반드시 참이어야 하는 선언(assertion).
- 근본적인 모호성 공리(fundamental ambiguity theorem)
- 한 리스트에 대한 참조점은 단일 객체로 취급될 수도 있고 노드를 담은 리스트의 첫 번째 노드로 취급될 수도 있다.
- 싱글턴(singleton)
- 단일 노드만을 가지는 연결 리스트.
- 포장자(wrapper)
- 호출자와 도움자 사이의 중재자 역할을 하는 메쏘드로, 종종 포장자를 사용하면 메쏘드를 에러가-덜-나도록 혹은 더 쉽게 요청할 수 있다.
- 도움자(helper)
- 직접적으로 호출자가 요청하지는 않지만 다른 메쏘드들이 부분적인 연산을 수행하는데 사용되는 메쏘드.
- 불변량(invariant)
- 한 객체에 대하여 (그 객체가 변경되는 동안은 제외하고) 언제나 참이어야만 하는 선언(assertion).

